
Visão Geral
Em Machine Learning, a gente costuma chamar aquela caixa preta que faz as previsões de modelo. Existem vários tipos, mas a estrela do momento é, sem dúvida, o modelo de linguagem.
Vamos ser sinceros: eles já existiam há um bom tempo, mas só furaram a bolha dev quando o ChatGPT apareceu. Um dos motivos é que os primeiros GPTs eram treinados com poucos dados. Conforme esse número cresceu, nasceram os LLMs (Large Language Models), e o resto é história.
No contexto do LangChain, o componente de Models é a peça fundamental. É ele que permite conectar sua aplicação a diferentes cérebros, seja o ChatGPT, o GPT-4, o Llama, entre outros. A versatilidade é enorme: você pode usar para responder perguntas, traduzir textos ou gerar conteúdo criativo.
Mas a mágica acontece quando você combina isso com outras ferramentas. Junte um Modelo com Prompts e você tem um chatbot que escreve poemas ou código. Junte com Indexes e você cria um motor de busca capaz de ler seus documentos e responder dúvidas baseadas neles.
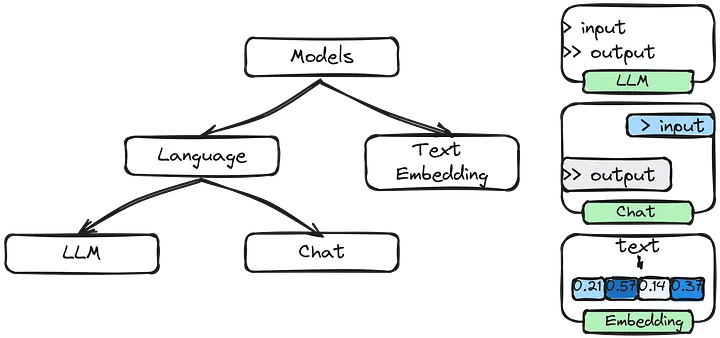
Modelos
O LangChain não te prende a um único modelo. Basicamente, temos três categorias principais aqui:
- LLMs: Usam APIs que recebem texto cru e devolvem texto cru.
- Chat Models: São mais estruturados, processam listas de mensagens (chat) e devolvem uma resposta.
- Text Embedding Models: Convertem texto em números (vetores) para que a máquina entenda o contexto.
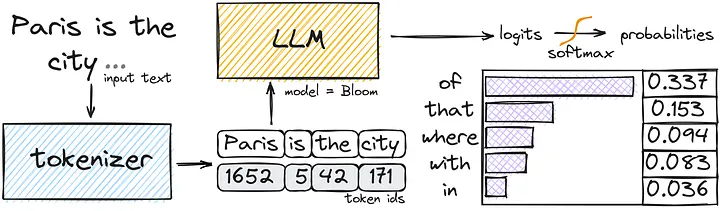
Tokenização
Computador não entende palavras, entende números. A tokenização é o processo de quebrar nossa linguagem em pedacinhos (tokens), que podem ser palavras inteiras ou partes delas.
Quando falamos de "geração de texto", na verdade estamos falando de geração de tokens. Imagine que queremos completar a frase:
"Paris é a cidade..."
O modelo calcula uma pontuação (chamada de logits) para todos os tokens possíveis e, usando uma função matemática, decide qual é a probabilidade da próxima palavra ser "luz", "grande" ou "feia".
Um detalhe importante: Em muitos modelos pré-treinados, o tokenizador e a arquitetura do modelo nascem juntos. Se você tentar usar o tokenizador de um modelo na arquitetura de outro, vai dar erro. É como tentar rodar um vinil numa fita cassete.
Proprietário vs. Open Source ?
Aqui você tem uma decisão estratégica para tomar.
De um lado, temos os modelos proprietários (OpenAI, Anthropic, co:here). São gigantes, performam incrivelmente bem, mas são caixas pretas pagas.
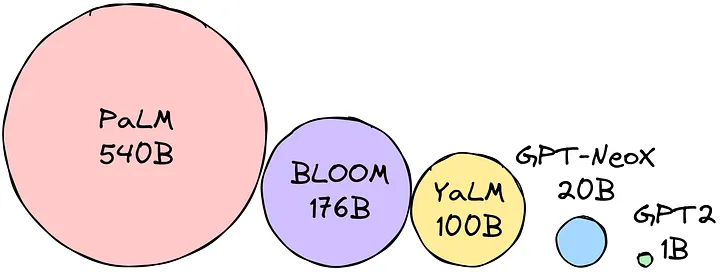
Do outro, temos os modelos open-source (geralmente hospedados no Hugging Face, como LLaMA, BLOOM ou Flan-T5). Eles costumam ser menores e menos capazes que um GPT-4 da vida, mas são "gratuitos" (você paga o processamento) e auditáveis.
É o clássico trade-off entre desempenho máximo e custo/controle.
Embeddings
Embeddings são representações numéricas compactas. Eles capturam o significado de uma palavra ou frase.
Para você ter uma ideia, veja como funciona a similaridade entre frases. Se pegarmos frases sobre "viagem", "cozinha" e "livros", e gerarmos os embeddings, o computador consegue agrupar o que é parecido.
Uma frase sobre "travesseiro de pescoço para voos" terá uma pontuação matemática muito próxima de "mochila leve para caminhada", e muito distante de "batedeira para bolos". É assim que a máquina entende contexto sem precisar de palavras-chave exatas.
LLMs e Chat Models
Embora um LLM tradicional possa "conversar", os Chat Models são otimizados para isso. As APIs deles esperam uma estrutura de mensagens (quem é o usuário, quem é o sistema, quem é o assistente).
Não precisamos necessariamente do LangChain para fazer uma pergunta simples ao GPT. Podemos usar a biblioteca direta da OpenAI:
import openai
def get_completion(prompt, model="gpt-3.5-turbo"):
# Cria a estrutura de mensagem
messages = [{"role": "user", "content": prompt}]
# Chama a API
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0, # Zero para respostas mais diretas/determinísticas
)
return response.choices[0].message["content"]
Para coisas simples, isso basta. Mas quando você precisa encadear pensamentos ou conectar fontes de dados, o LangChain vira seu melhor amigo.
Hardware
Se você decidir rodar modelos localmente (na sua própria máquina), precisa fazer conta. O tamanho do modelo em bytes é, grosseiramente, o número de parâmetros vezes a precisão escolhida.
Quer rodar o BLOOM-176B (176 bilhões de parâmetros) com precisão bfloat16 (2 bytes)?
A conta é: 176 bilhões * 2 bytes = 352 GB.
Pois é. A menos que você tenha um cluster de GPUs em casa, isso é inviável.
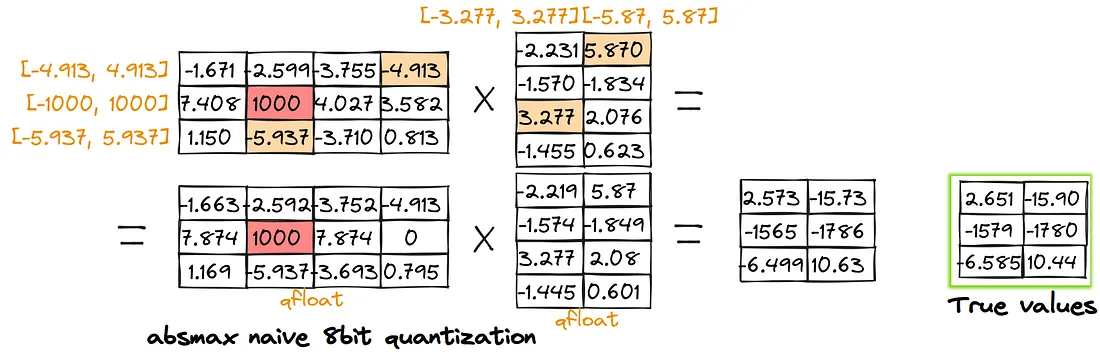
Quantização
Para resolver isso, usamos a quantização. É uma técnica de compressão. Basicamente, reduzimos a precisão dos pesos do modelo (de 16 bits para 4 bits, por exemplo). Perdemos um pouquinho de "inteligência", mas o modelo fica muito mais leve e rápido.
No código, geralmente parece com isso:
# Configurando para quantização em 4 bits
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
Rodando apenas na CPU
Muita gente se surpreende com isso, mas você não é obrigado a ter uma GPU da NASA. Dá para rodar LLMs usando apenas a CPU. Vai ser lento? Vai. A resposta pode levar minutos. Mas funciona até num Raspberry Pi se você tiver paciência.
Veja como fazer isso com um modelo Llama quantizado:
from langchain.llms import CTransformers
# Inicializa o modelo localmente
llm = CTransformers(
model="llama-2-7b-chat.bin", # Arquivo do modelo baixado
model_type="llama",
config={
"max_new_tokens": 256,
"temperature": 0.1,
},
)
# Roda o chain
llm_chain = LLMChain(prompt=prompt, llm=llm, verbose=True)
Isso democratiza bastante o acesso. Não é rápido, mas prova que a tecnologia está ficando cada vez mais acessível.